大 创 实(shí) 验 室
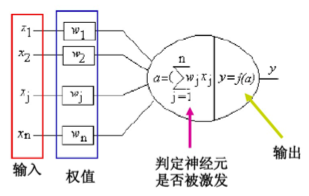
聊聊人工智能芯片人工智能芯片主要包括NVidia GPU、Google的TPU、Intel的(de)Nervana、IBM的(de)TreueNorth、微(wēi)软的DPU和BrainWave、百度(dù)的(de)XPU、Xilinx的(de)xDNN、寒武纪芯片、地平线以及(jí)深(shēn)鉴科技的AI芯(xīn)片(piàn)等,基本上是(shì)GPU、FPGA、神(shén)经网络(luò)芯片三(sān)分天下的趋势,三种芯(xīn)片各有(yǒu)各自的优劣(liè),都在面向自己(jǐ)独特的细分市场(chǎng)。本章先聊一(yī)聊深度神经网(wǎng)络和NVidia GPU的崛起。 人工智能(néng)的(de)终极目标是模拟人脑,人脑大概有1000亿个神经元,1000万(wàn)亿个突(tū)触,能够(gòu)处理复(fù)杂的视觉、听觉、嗅觉、味觉(jiào)、语(yǔ)言能力、理解能力、认知能力(lì)、情感控制、人(rén)体复杂(zá)机构控制、复(fù)杂心理和生理(lǐ)控(kòng)制,而(ér)功耗(hào)只有10~20瓦。 这是人脑基本神经元和突触(chù): 这是人工(gōng)神经元模拟神经元(yuán):
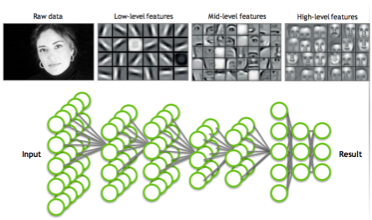
输(shū)入模(mó)拟神经(jīng)元输入电信号,权值模拟(nǐ)神经元之(zhī)间的突触连接,激活函数模拟突触之间的电信号传导。 早在1981年(nián)David Hubel和Torsten Wiesel就(jiù)发现了人的(de)视觉系(xì)统的信息处(chù)理是分级的,因此获得了诺(nuò)贝尔医(yī)学奖。如(rú)图所示,从视网膜出发,经过(guò)低(dī)级的(de)V1区(qū)边缘特征(zhēng)提取(qǔ),到V2区识别基本形状或目标的局部(bù),再到高层的目标(biāo)识别(例如识别(bié)人脸(liǎn)),以(yǐ)及到更高层的(de)前额叶皮层进行分类判断(duàn)等,人们意识到高(gāo)层特征是低层(céng)特征的(de)组(zǔ)合,从低层到高层越(yuè)来(lái)越抽象,越来越能(néng)表(biǎo)达语义或者意图。 深(shēn)度(dù)神经网络模(mó)型模(mó)拟人脑识别的分(fèn)层(céng)识(shí)别过程(chéng):
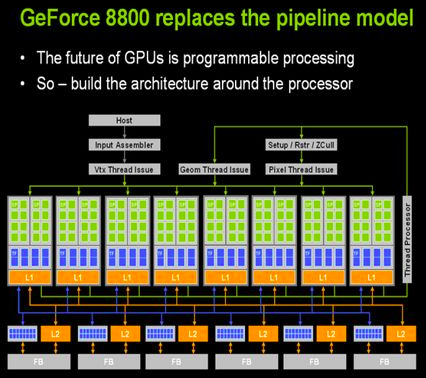
深度神经网络的输入层模拟视觉(jiào)信号(hào)的输入,不同的隐藏层模拟不同级别的(de)抽象,输出层模(mó)拟输出的对象分类或者语义等。 从上(shàng)图的(de)典型的人脸(liǎn)识别的训练任务来看,按照10层深(shēn)度神经网络、训练上(shàng)百万(wàn)张图片,大概需要30 Exaflops的(de)计算(suàn)能力(lì),如果还是用CPU来做训练,大概需要(yào)训练一年的时间,这显(xiǎn)然是无法(fǎ)忍受的速度,亟待(dài)需要计算能力更强的人工神经(jīng)网络芯片出现。 NVidia GPU的崛起可(kě)能有很(hěn)多(duō)人会问,目前在人工智能领域(yù),NVidia GPU为什么(me)具有(yǒu)无可撼动的霸(bà)主(zhǔ)地(dì)位,为什(shí)么AMD的GPU和NVidia GPU性能相差不多,但是在人工智能领域的(de)受欢迎的程度却有(yǒu)天(tiān)壤之别。 我们知道GPU原本就是显(xiǎn)卡(kǎ),它是(shì)为游戏和渲染而生的,它里面(miàn)核心运行单元是(shì)shader,专门用作像素、顶点(diǎn)、图形等渲染用(yòng)的。 NVidia在2006年的时候跨时代的推出(chū)了统(tǒng)一计算设备(bèi)架构CUDA(Compute Unified Device Architecture)以及对(duì)应(yīng)的G80平台,第一次让GPU具有可编(biān)程性(xìng),让GPU的核心(xīn)流式处理器Streaming Processors(SPs)既具(jù)有(yǒu)处理像(xiàng)素、顶点、图形等(děng)渲染(rǎn)能力,又同时具(jù)备通用的单精度浮点处理能力,NVidia称之(zhī)为GPGPU(General Purpose GPU),黄教主的野(yě)心(xīn)是让GPU既(jì)能做游戏和渲染也做并(bìng)行度(dù)很高的通用计算。
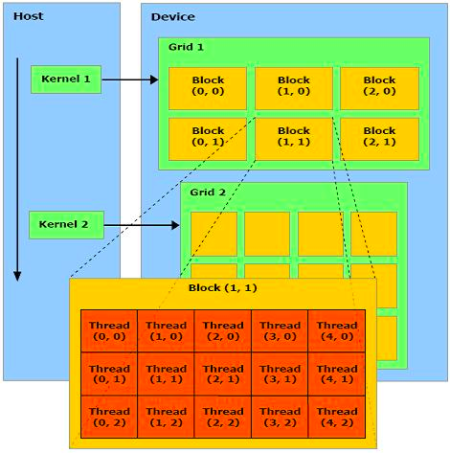
G80有16组流式处(chù)理器Streaming Processors(SPs),每组(zǔ)SP里有(yǒu)16个(gè)计算核心,一共128个独(dú)立的计算核心,单精度峰值计算能力可(kě)达330 Gflops,而同期主流的Core2 Duo CPU只有50 Gflops的处(chù)理能力,更为重要的是从G80架构开始,GPU开始支持可编程(chéng),所有的计(jì)算密集型的并行任务都有可能(néng)通过程序移植在GPU上运行起来。 CUDA的编程模型CUDA将(jiāng)GPU的计算单(dān)元抽象成3个编程层次(cì):Grids、Blocks和Threads,一个(gè)CUDA kernel在执行的前会先把(bǎ)数据和指(zhǐ)令传到(dào)GPU上,在执行(háng)的时候会使用若干个Grids,一个Grid里含有多个Blocks,一个Block里含有多个Threads,调(diào)度上一个(gè)Block的Threads会调度(dù)到一(yī)个独立的(de)Streaming Processors上执行,而16/32个Threads称为(wéi)一个Warp,Warp是GPU上(shàng)指令调度(dù)的最小(xiǎo)单元,一个(gè)Warp会同(tóng)时运(yùn)行(háng)在16/32个计算核心上(shàng)。
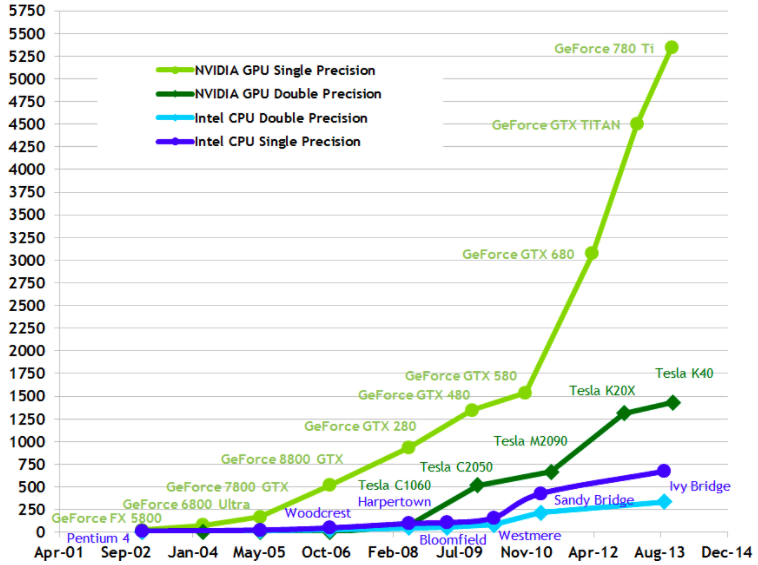
性(xìng)能增长(zhǎng)远超CPU战略(luè)NVidia从2006年推出Tesla架构以(yǐ)来,不断的(de)更新(xīn)架(jià)构和(hé)性能(néng),陆续(xù)推出了(le)Femi、Maxwell、Pascal还有最新的Volta架构,基本上保持着2年(nián)性能翻1倍的(de)增长态势(shì)。 而(ér)对CPU的(de)性能(néng)加速比(bǐ),在(zài)单精度(dù)计算能力(lì)上保(bǎo)持着遥(yáo)遥领先的态势(shì),并且拉开的差距越来越大。
深(shēn)度神经网络+NVidia GPU掀起(qǐ)人工智能浪潮深度神经网络+NVidia GPU掀(xiān)起了业(yè)界的人工智能(néng)浪潮,不(bú)得不说这只是老黄整(zhěng)体战(zhàn)略(luè)的一个副产(chǎn)品,谁也没有想(xiǎng)到,高性能计算领域的一个分支--人(rén)工智能会如此火爆。 2011年,负(fù)责谷(gǔ)歌(gē)大脑的吴恩达(dá)通(tōng)过让深(shēn)度神经网络训练图片,一周之内学会(huì)了识别猫,他(tā)用了12片GPU代替了2000片CPU,这是世界(jiè)上第一(yī)次让机器(qì)认识猫。 2015年,微(wēi)软研(yán)究院用GPU加速的深(shēn)度神经网络(luò),在ImageNet比赛中获(huò)得(dé)了多项击败(bài)人的辨(biàn)识准确度,这是(shì)第一次(cì)机器视觉的识别率打败了(le)人眼(yǎn)的识别率(错误率5%),可以认为是人(rén)工智能史上的一(yī)个(gè)重(chóng)要里程碑事件。 2016年,谷歌旗(qí)下Deepmind团队研发的机器人AlphaGo以(yǐ)4比(bǐ)1战胜世界围(wéi)棋冠(guàn)军职业九(jiǔ)段棋手李(lǐ)世石(AlphaGo的神经网络训练用了(le)50片GPU,走棋网络(luò)用了174片GPU),引发(fā)了围棋(qí)界的轩然大波,因(yīn)为(wéi)围棋一(yī)直被认为是人类智力较量的(de)巅峰,这(zhè)可以看做(zuò)是(shì)人工智能史上的又一个重大里程碑事件(jiàn)。
文章分(fèn)类:
行(háng)业新闻
|